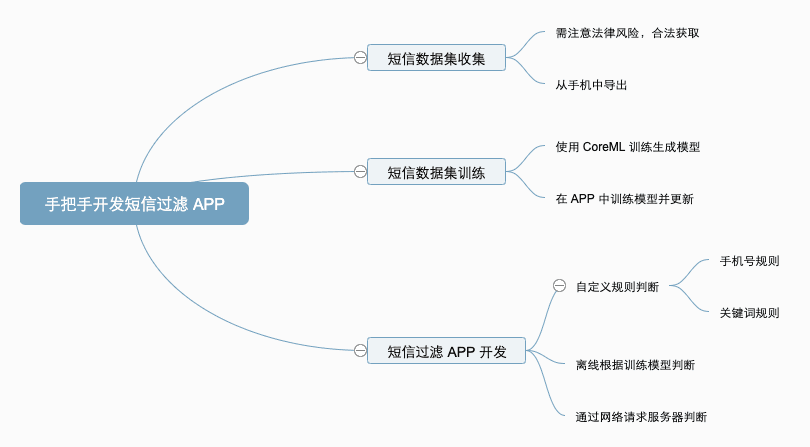
短信フィルタリング APP 開発#
本文は搜狐技術製品 - 短信フィルタリング APP 開発に掲載されています。
自分の短信フィルタリング APP を開発したいと思っていましたが、具体的に実施することはありませんでした。今、ようやく心を落ち着けて、開発しながら全体の開発プロセスを記録することにしました。
ゴミ短信サンプル#
最初の問題は、ゴミ短信をフィルタリングするためには、まずどれがゴミ短信なのかを識別しなければならないということです。どうやって識別するのでしょうか?
以前、鋼管のカウントを識別するための経験を参考に、CoreML を使ってテキストモデルをトレーニングすることに決めました。しかし、問題は、モデルをトレーニングするための短信データセットをどうやって入手するかということです。
最初はインターネットでゴミ短信のサンプルを探そうと思いましたが、長い間探しても見つかりませんでした。そこで、自分と家族のスマートフォンにある短信を使うことを思いつきました。結局、スマートフォンの短信は一般的に削除されず、数千件はありますし、ゴミ短信や勧誘、広告なども豊富にあります。
そこで問題は、iPhone の短信をどうやってエクスポートするかということです。
ここでもかなり調べましたが、見つけたサードパーティのソフトウェアはほとんどが有料でした。最終的に無料でエクスポートする方法を見つけました。
まず、スマートフォンを暗号化せずにコンピュータにバックアップします。以下の図のように、Back up all the data on your iPhone to this Macを選択し、Back Up Nowをクリックしてバックアップが完了するのを待ちます。バックアップが完了したら、Manage Backupsをクリックします。

Manage Backupsをクリックすると、以下の画面が表示され、バックアップの記録が確認できます。右クリックしてShow In Finderを選択し、フォルダを開きます。

次に、バックアップが保存されているディレクトリが開かれます。この時、3d0d7e5fb2ce288813306e4d4636395e047a3d28という名前のファイルを見つける必要があります。このファイルが短信バックアップのデータベースファイルです。さて、どうやって見つけるのでしょうか?バックアップディレクトリにはたくさんのフォルダがあるので、混乱するかもしれませんが、簡単です。検索を利用します。右上の検索をクリックし、このファイル名を直接入力すれば大丈夫です。検索範囲は現在のフォルダに設定してください。

検索結果は以下の通りです:

このファイルを別の場所、例えばデスクトップにコピーし、データベースソフトウェアで開きます。例えばSQLPro for SQLLiteを使用して、以下のように開きます。

このファイルを観察すると、電話番号と短信の記録が異なるテーブルに分かれていることがわかります。必要な内容を取得するために SQL を記述する必要があります。SQL の内容は以下の通りです。参考にしたのはSQL to extract messages from backupです。上の図のQueryを選択し、以下のコマンドを入力します:
SELECT datetime(message.date, 'unixepoch', '+31 years', '-6 hours') as Timestamp, handle.id, message.text,
case when message.is_from_me then 'From me' else 'To me' end as Sender
FROM message, handle WHERE message.handle_id = handle.ROWID AND message.text NOT NULL;
右上の実行ボタンをクリックすると、短信がすべてフィルタリングされているのが確認できます。

すべての行を選択し、右クリックしてExport result set as を選択し、CSVとしてエクスポートすれば、Excel 形式のファイルが得られます。

これで必要な短信サンプルを取得できました。
ゴミ短信トレーニング識別#
サンプルが得られたので、次に識別のトレーニング方法を考えます。Apple の CoreML を使用して識別する予定ですが、どうやって使うのでしょうか?サンプル形式の要件はどのようなものでしょうか?トレーニングにはどれくらいの時間がかかりますか?
まず、テキストトレーニングのCoreMLプロジェクトを作成します。Xcode を選択し、Open Developer ToolをクリックしてCoreMLを開きます。以下の図のようにします。

次にフォルダを選択し、New Documentをクリックします。以下のようにします。

次にText Classificationを選択します。以下の図のようにします。

続いてプロジェクトの名前と説明を入力します。

右下の作成ボタンをクリックし、メイン画面に入ります。以下のようになります。

Training Dataの詳細説明をクリックすると、CoreMLが要求するテキスト識別の形式が表示されます。JSONとCSVファイルがサポートされており、形式は以下の通りです。

JSON 形式は以下の通りです:
// JSON file
[
{
"text": "映画は素晴らしかった!",
"label": "positive"
}, {
"text": "非常に退屈。寝てしまった。",
"label": "negative"
}, {
"text": "まあまあでした。",
"label": "neutral"
} ...
]
CSV 形式は、1 列目がtext、2 列目がlabelです。
| text | label |
|---|---|
| これは普通の短信です | label1 |
| これはゴミ短信です | label2 |
前のステップで短信を CSV 形式にエクスポートしたので、ここでは上の図の形式に変更するだけです。残る問題は、label にはどのような値があるかということです。
label の値を確認するためには、システムの短信フィルタリングロジックを確認する必要があります。サポートされているフィルタリングカテゴリは何か?そうでなければ、自分が実現したい分類をグループ化しても、最後にシステムがサポートしていなければ困ります。
短信フィルタリングカテゴリ#
システムの短信フィルタリングロジック#
SMS and MMS Message Filteringを参考にすると、開発者は新しいグループを作成する権限がなく、未知の連絡先からのSMSまたはMMSに対してのみ、指定されたカテゴリにフィルタリングすることができます。
ここで注意が必要なのは、文書によると、短信フィルタリングは iMessage や連絡先の短信のフィルタリングをサポートしておらず、未知の連絡先からのSMSとMMSのみをサポートしているということです。
短信フィルタリングは、ローカル判断フィルタリングとサーバー判断フィルタリングに分かれます。示意図は以下の通りです。
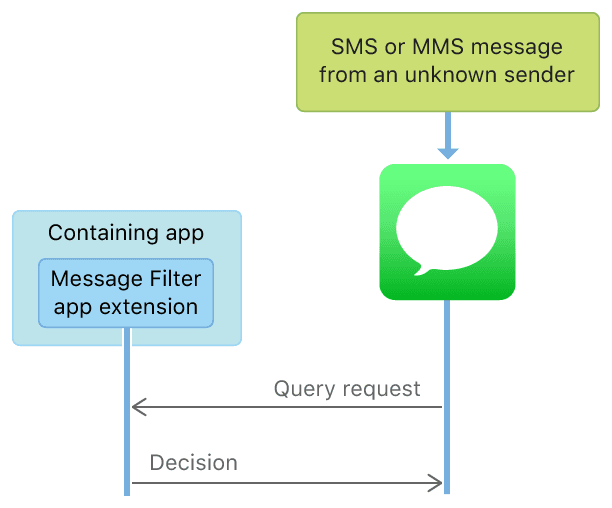
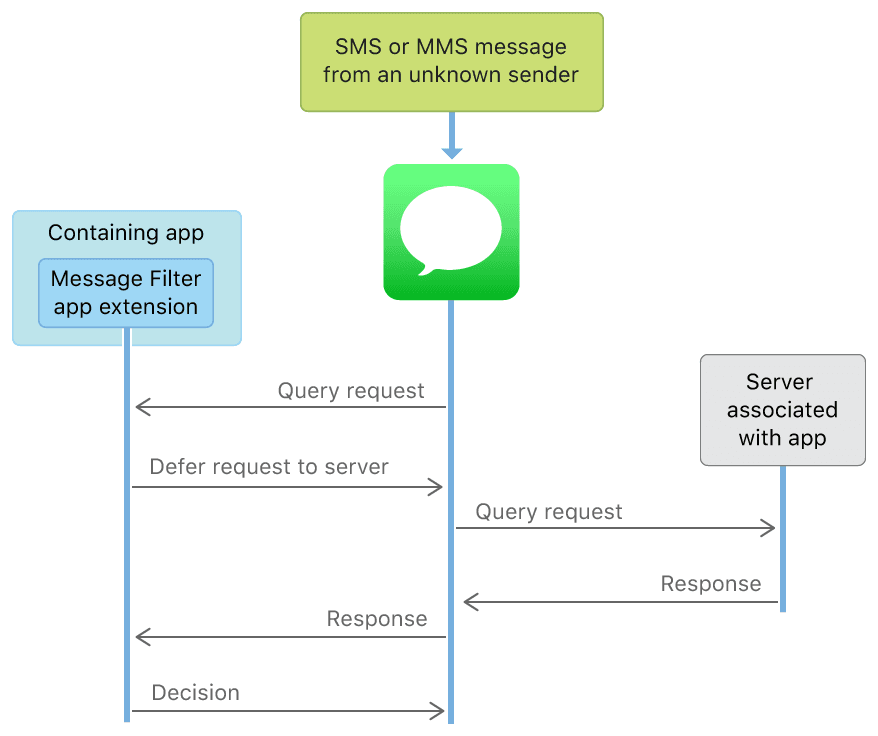
文書によると、たとえサーバー側でフィルタリングを行っても、APP は直接ネットワークにアクセスできず、システムが設定されたサーバーとやり取りします。また、App Extension は共有グループにデータを書き込むことができないため、短信は App Extension 内でのみ取得でき、保存やアップロードはできず、プライバシーとセキュリティが保たれます。サーバー側のフィルタリングの詳細な実装については、Creating a Message Filter App Extensionを参照してください。
次に、サポートされているフィルタリングタイプ、ILMessageFilterActionを見てみましょう。
大分類は 5 つのタイプをサポートしています:
- none
情報が不十分で判断できず、情報を表示するか、さらにサーバーに判断を依頼します。 - allow
正常に情報を表示します。 - junk
正常に情報を表示するのを阻止し、ゴミ短信カテゴリに表示します。 - promotion
正常に情報を表示するのを阻止し、プロモーション情報カテゴリに表示します。 - transation
正常に情報を表示するのを阻止し、取引情報カテゴリに表示します。
その中でさらに細分化されたサブカテゴリ、ILMessageFilterSubActionについては、具体的な意味をILMessageFilterSubActionで確認できます。
- none
- promotion のサブカテゴリには
- others
- offers
- coupons
- transation のサブカテゴリには
- others
- finance
- orders
- reminders
- health
- weather
- carrier
- rewards
- publicServices
ここでは大分類に対してのみ処理を行い、具体的なサブカテゴリの詳細なフィルタリングは行わないため、トレーニングする label の値は以下のように明確になります:
- allow
- junk
- promotion
- transation
次に、エクスポートした短信のCSVファイルに対して、各短信に対応する label を追加します。ここでは手作業で行う必要があります。サンプルのサイズと label の定義が後の識別の正確性を決定します。また、後のサブカテゴリの実装のために、実際に正確にラベル付けを行うことをお勧めします。例えば、promotion の中のものを junk に分類しないようにしましょう。。。
各短信サンプルにラベルを付け終わったら、Create MLにインポートしてトレーニングを行い、必要なモデルを生成します。手順は以下の通りです。
まず、データセットをインポートします。

次に左上のTrainをクリックします。

トレーニングが完了したら、Preview をクリックして、短信テキストをシミュレーションし、出力の予測を確認します。以下の図のようになります。

最後に、モデルをエクスポートして APP で使用します。

APP 開発#
新しいプロジェクトを作成し、new bing 生成画像を使用して APPIcon をデザインし、ChatGPT-4 を使って APP 名を生成します。その後、Message Filter Extensionターゲットを追加します。以下の図のようにします。

MessageFilterExtension.swiftの中には、Apple が基本的なフレームワークを実装してくれているのが見えます。必要なのは、フレームワークの対応する // TODO: の部分にフィルタリングロジックを追加することだけです。
次に、トレーニング結果セットをプロジェクトにインポートします。注意点は、ターゲットに主プロジェクトとMessage Filter Extensionのターゲットをチェックする必要があることです。モデルを使用してフィルタリングを実現するためです。
具体的な使用方法は以下の通りです:
import Foundation
import IdentityLookup
import CoreML
import IdentityLookup
enum SMSFilterActionType: String {
case transation
case promotion
case allow
case junk
func formatFilterAction() -> ILMessageFilterAction {
switch self {
case .transation:
return ILMessageFilterAction.transaction
case .promotion:
return ILMessageFilterAction.promotion
case .allow:
return ILMessageFilterAction.allow
case .junk:
return ILMessageFilterAction.junk
}
}
}
struct SMSFilterUtil {
static func filter(with messageBody: String) -> ILMessageFilterAction {
var filterAction: ILMessageFilterAction = .none
let configuration = MLModelConfiguration()
do {
let model = try SmsClassifier(configuration: configuration)
let resultLabel = try model.prediction(text: messageBody).label
if let resultFilterAction = SMSFilterActionType(rawValue: resultLabel)?.formatFilterAction() {
filterAction = resultFilterAction
}
} catch {
print(error)
}
return filterAction
}
}
次に、MessageFilterExtension.SwiftのofflineAction(for queryRequest: ILMessageFilterQueryRequest) -> (ILMessageFilterAction, ILMessageFilterSubAction)メソッドを呼び出します。以下のようにします:
@available(iOSApplicationExtension 16.0, *)
private func offlineAction(for queryRequest: ILMessageFilterQueryRequest) -> (ILMessageFilterAction, ILMessageFilterSubAction) {
guard let messageBody = queryRequest.messageBody else {
return (.none, .none)
}
let action = MWSMSFilterUtil.filter(with: messageBody)
return (action, .none)
}
ここで注意が必要なのは、APP の最低バージョン設定です。ILMessageFilterSubActionは iOS 16 以上のデバイスでのみサポートされ、ILMessageFilterSubActionは iOS 14 以上でサポートされています。
より詳細なSubActionフィルタリングを実現したい場合は、上記の短信データセットの label をより詳細な label に変更し、モデルをトレーニングして判断に使用します。
また、ILMessageFilterQueryRequestではsenderとmessageBodyを取得できるため、特定の電話番号に対してカスタムルールを設定したい場合は、APP 内でルールを設定し、Group を介して Extension に共有し、上記のメソッドでルールを照合する必要があります。
まとめ#
上記の手順を通じて、皆さんが自分の短信フィルタリング APP を開発できることを信じています。
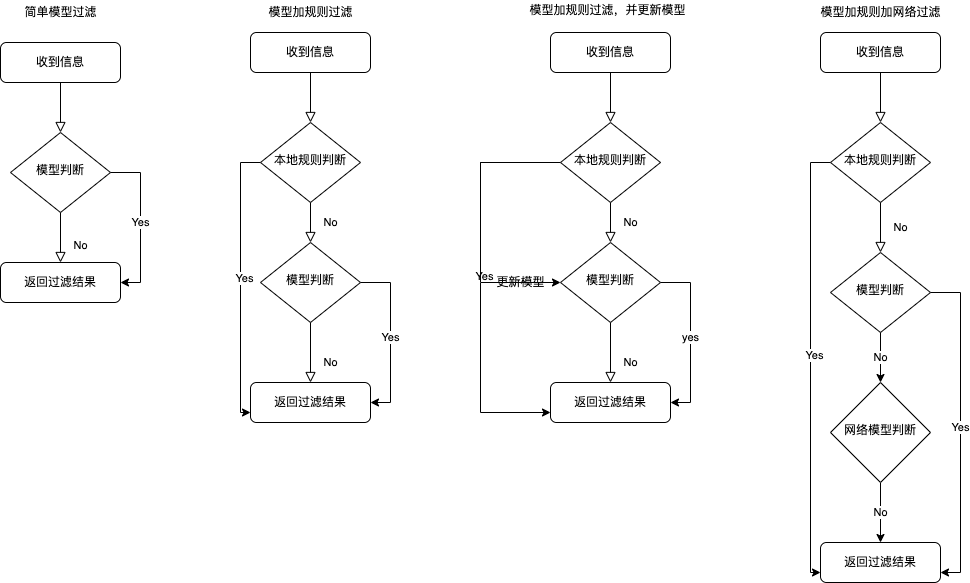
上記の手順は、固定のトレーニングモデルを使用してマッチングのロジックを実現するもので、手順は以下の通りです:
- 短信データセットを取得する
- CoreML を使用してデータセットをトレーニングし、モデルを生成する
- プロジェクト内でモデルを使用して判断を行う
この方法で生成されたモデルはデータが固定されており、モデルを更新するたびに再トレーニングしてインポートし、APP を更新する必要があります。より良い方法はないでしょうか?
例えば、APP 内でトレーニングしながら更新できるのでしょうか?または、ローカルルールとローカルモデル、ネットワークモデルを組み合わせる方法はどうでしょうか?
仮定の提案 1:
まず、APP 内でトレーニングしながら更新する大まかな考え方は以下の通りです:
モデルを更新するには、データの内容とデータの分類を知る必要があります。したがって、APP 内でモデルをトレーニングする場合、分類を取得するための別の方法が必要です。そうでなければ、モデルを使って分類を得てから再度モデルをトレーニングするのはあまり意味がありません。したがって、カスタムルールを通じてデータ分類を取得し、そのデータとデータ分類を使用してモデルを更新する方法は実行可能であると思われます。
仮定の提案 2:
次に、より完全な方法を考えます。すなわち、ローカルルール、ローカルモデル、ネットワークモデルを組み合わせる方法です:
ロジックは、まずローカルルールでマッチングし、ローカルルールでマッチングできない場合はローカルモデルでマッチングし、ローカルモデルでもマッチングできない場合はサーバーにリクエストを送信します。サーバーには別のトレーニング更新モデルがあり、対応する分類を取得します。最後に、毎回更新時にサーバーの最新モデルをプロジェクトに更新します。
仮定の提案 3:
提案 2 ではネットワークモデルを使用する必要がありますが、前提としてサーバーにトレーニング更新モデルが存在する必要があります。この前提が存在しない場合、ローカルルールとローカルモデル、時折取得する更新データセットだけで、ローカルモデルをオンラインで更新する方法はあるのでしょうか?
現在、ローカルモデルは APP の主バンドルに直接追加されています。初回起動時に APP と Extension の共有グループにコピーし、APP を開くたびにモデルに更新があるかどうかを確認し、更新があればこのディレクトリ下のモデルファイルをダウンロードして置き換えることを考慮できます。Extension 内では、このディレクトリ下のモデルファイルを URL で取得してフィルタリングを行います。
いくつかの提案のフローチャートは以下の通りです:
まとめは以下の通りです: